Data-analytics
[R] 치킨 대격변 5년 - 서울시 1인 가구 비율에 따른 치킨 데이터 분석
by Roseline Song | March 25, 2019
치킨 대격변 5년 : 서울시 1인 가구 비율에 따른 치킨 데이터 분석
1인 가구 비율과 치킨 통화 건수 비율의 상관관계를 밝힌다. 결과가 아주 흥미롭다. 그래프를 보는 순간 ‘응???’이라는 반응이 나올 것이다.
※ 데이터는 SK 데이터 허브의 월별 서울시 치킨 통화 건수와 공공데이터포털의 서울시 분기별 세대당 인구수 데이터 파일을 병합 및 재가공했다.
결과 : 갭마인더 그래프 확인하기
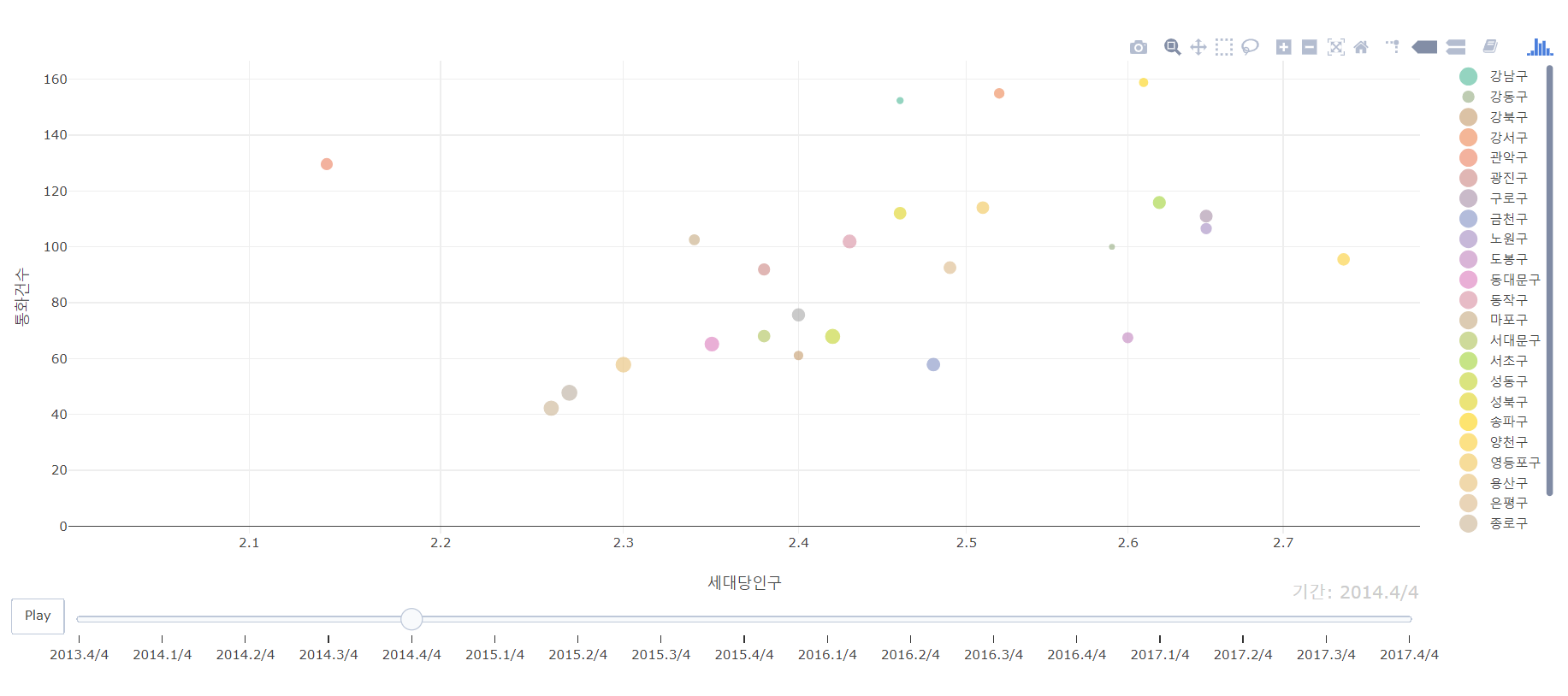
인사이트 1 : “배달앱 사용의 증가”
20대, 1인 가구 공략 : “통화보다는 배달앱이 더 편한 밀레니엄 세대”
2014년에서 2015년도까지는 통화건수가 세대당 인구 수에 비례하는 관계를 보였다. 하지만, 2016년부터는 1인 가구 비율이 늘어나면서 데이터 포인트가 전체적으로 왼쪽으로 이동하고, 통화 건수도 줄어드는 양상을 보인다. 데이터가 이상하다. 1인 가구가 치킨을 적게 시켜먹는다니?
1인 가구 비율이 높을 수록 치킨을 더 적게 시켜먹는 걸까? 그렇지 않다. 인터넷에 떠돌아다니는 자료만 봐도 1인 가구, 20대 젊은 세대들이 가장 치킨을 많이 시켜먹는다.
그렇다면 왜 저런 결과가 나타난 것일까? '통화건수' = 치킨 배달수라고 보면 안된다. 이는 완전히 배달 건수를 반영한 게 아니다. 배달앱이 있기 때문이다.
갭마인더 그래프를 실행시키면 배달의 민족이 출시된 2015년부터 통화건수가 전체적으로 낮아지기 시작한다. 치킨 배달 건수가 줄어든 게 아니다. ‘통화’가 줄고 ‘앱’으로 시키는 배달이 증가한 것이다.
따라서, 20대, 1인 가구를 공략하고 싶다면 아직 배달앱을 지원하고 있지 않은 치킨 매장은 배달앱 활용을 시작해야한다.
인사이트 2 : “치킨은 관악구에서 튀기자”
관악구는 치킨 수요가 많다.
13년부터 17년까지 관악구의 1인 가구 비율은 줄곧 높았다. 하지만 특이한 것은 1인 가구 비율이 높은 데도 통화 건수가 높다는 것이었다. 관악구는 배달앱을 쓰지 않는 사람들만 모인 걸까??? 혹은 관악구의 치킨 매장들이 배달앱을 지원하지 않는 걸까??? 둘 다 아니다.
관악구는 앱을 통한 주문과는 별개로 그냥 주문 건 수 자체가 월등히 많기 때문이다. 관악구는 서울대, 신림동 고시촌, 신혼부부와 같이 젊은 세대들이 밀집해 있는 지역이다. 앱이든 전화든 치킨 배달 건 수가 많을 것이다.
데이터에서 드러난 신림동 고시촌의 격변
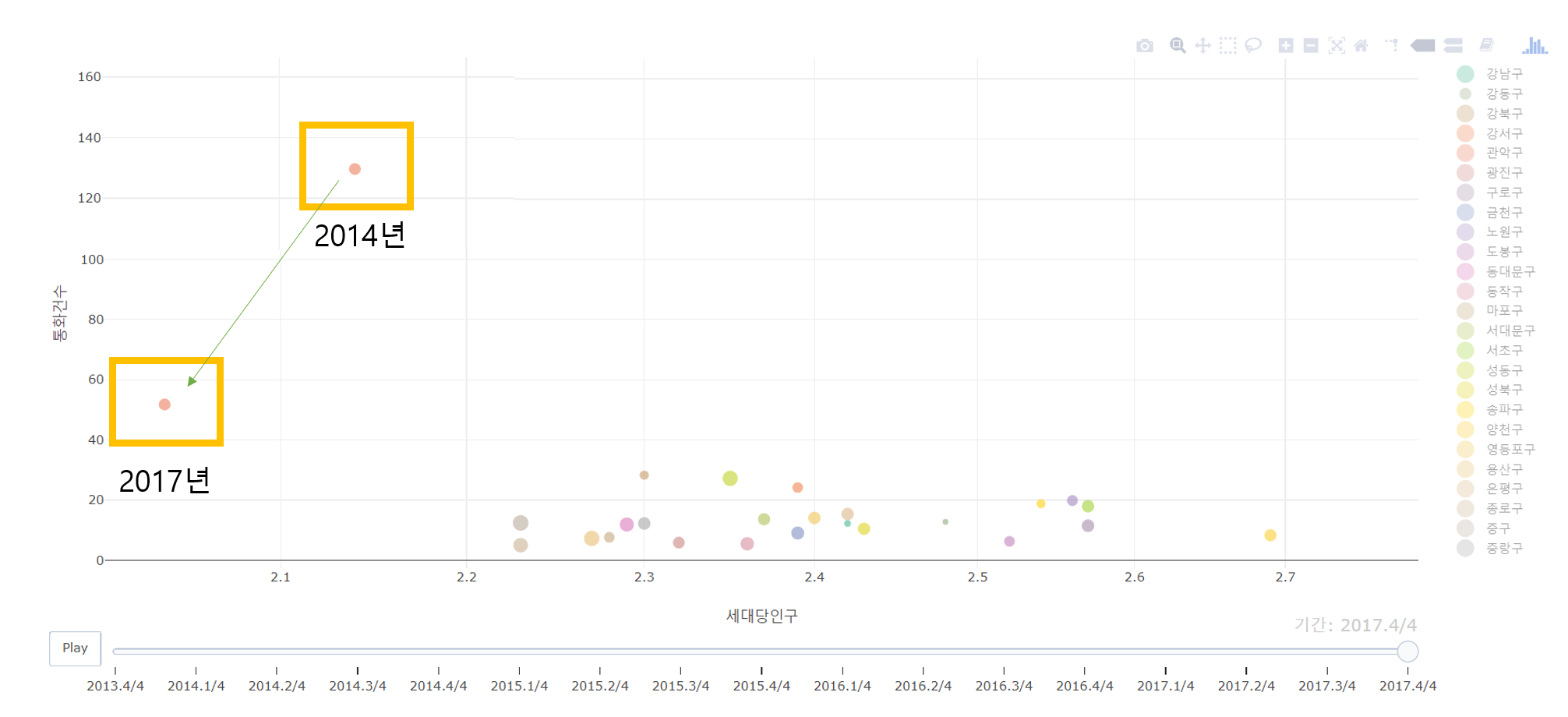
2017년 즈음 사시 폐지로 신림동 고시촌이 위기를 겪은 적이 있었다. 갭마인더 그래프에서 관악구 점을 더블 클릭해서 다시 플레이해보자. 다른 지역에 비해 여전히 높긴 하지만 지난 5년에 비해 가장 낮은 수치다. 왜? 청년들이 없기 때문에. 사시가 폐지되어 상권이 망해갔기 때문이다. 다행히 지금은 신림동의 화려한 부활이라는 기사가 뜰 정도로 다시 살아났다.
R 코드
clean_chicken_data.r
오직 chicken.xlsx를 위한 함수다. 분기별로 데이터를 보여주고 싶었기에 월별 데이터를 모두 가공해야했다. 그러나 시간도 없고, 일일이 엑셀을 손볼 수는 없었다. 다행히 SK에서는 5년 동안 비슷한 양식으로 업로드 해왔기 때문에, 함수를 만들어 이 문제를 해결할 수 있었다.
clean_chicken_data <- function(year) {
library(readxl)
dir_path <- paste("dataset/chicken_", year, sep="")
files <- list.files(dir_path)
ch <- data.frame()
for (f in files) {
print("####### DATA LOAD ... ########")
print(f)
######## 데이터 로드 ########
file_path <- paste(dir_path, f, sep="/")
raw_df <- read_excel(file_path, skip=1)
######## 데이터 가공 ########
# for문 밖에서 해도 되지만 메모리를 효율적으로 쓰기 위해.
# 인덱싱
if(year==2017){
idx <- c(1,2,3,4,6,9)
} else {
idx <- c(1,2,3,4,6,8)
}
tmp <- raw_df[, idx]
colnames(tmp) <- c("기준일", "요일", "성별", "연령대", "시군구", "통화건수")
# lapply : 여러 컬럼 한꺼번에 데이터타입 바꾸는 법
cols <- c("성별", "연령대", "시군구")
tmp[cols] <- lapply(tmp[cols], factor)
tmp$통화건수 <- as.numeric(tmp$통화건수)
# 데이터 병합
ch <- rbind(ch, tmp)
} # for 문
############### 분기별 정리 #################
date <- as.Date(as.character(ch$기준일), format = "%Y%m%d")
lt <- unclass(as.POSIXlt(date))
date_vector <- c("날짜", "연", "월", "일")
ch[, date_vector ] <- with(lt,
data.frame(날짜 = date
, 연 = year + 1900
, 월 = mon + 1
, 일 = mday))
# 인덱싱
ch <- cbind(ch[,8:9], ch[,3:6])
# Quater
ch$분기별 <- cut(ch$월,
br=c(0,3,6,9,12),
labels=c("1Q","2Q","3Q","4Q"))
return(ch)
}
서울시 치킨 Gapminder
Gapminder는 故 한스 로슬링 교수님이 만드신 통계 분석 서비스이다. 우리에게 익숙한 정적인 그래프에서 벗어나, 인터랙티브 그래프를 만들 수 있다. 데이터 포인트 위에 마우스를 올려놓으면 데이터의 정보가 뜨기도 하고, 연도에 따라 데이터 포인트가 움직이기도 한다.
chicken_minder.r
서울시 구별 세대당 인구 수에 따른 통화 건수 변화를 갭마인더로 표현한다. 세대당 인구 수가 낮을 수록 1인 가구의 비율이 높다.
library(dplyr)
library(COUNT)
library(readxl)
library(plotly)
library(tidyverse)
library(gapminder)
source("clean_chicken_data.R", encoding = 'utf-8')
############# Chicken Data ##############
years <- c(2013, 2014, 2015, 2016, 2017)
# Rbind all chicken files
chs <- data.frame()
for(y in years) {
tmp <- clean_chicken_data(y)
chs <- rbind(chs, tmp)
}
head(chs)
tail(chs)
# 연도별, 분기별, 시군구, 통화건수
ch_by_quater <- chs %>%
group_by(연, 분기별, 시군구) %>%
summarise(통화건수 = mean(통화건수))
View(ch_by_quater)
head(ch_by_quater)
tail(ch_by_quater)
############# Seoul Population Data ##############
seoul_pop <- read_excel("dataset/seoul_pop.xlsx", skip=1)
# Remove ',' in columns & Type casting
seoul_pop$세대 <- gsub('[,]', '', seoul_pop$세대)
seoul_pop$계 <- gsub('[,]', '', seoul_pop$계)
# mean of 세대당 인구 by 기간별, 구별
pop_by_quater <- seoul_pop %>%
group_by(기간, 자치구) %>%
summarise(세대당인구 = mean(세대당인구))
# Cbind Chicken, Seoul Population
df <- cbind(ch_by_quater, pop_by_quater)
# Indexing
df2 <- df[, c(5,3,4,7)]
# 세대, 계
df2 <- cbind(df2, seoul_pop[c("세대", "계")])
df2["세대"] <- as.numeric(as.character(df2$세대))
df2["계"] <- as.numeric(as.character(df2$계))
# Plot
p <- df2 %>%
plot_ly(
x = ~세대당인구,
y = ~통화건수,
size = ~세대,
color = ~시군구,
frame = ~기간,
text = ~시군구,
hoverinfo = "text",
type = 'scatter',
mode = 'markers'
) %>%
layout(
xaxis = list(
type = "log"
)
)
ggplotly(p, tooltip = "text")
Subscribe via RSS